Nccl Allreduce
起因
这篇文章的起因在于阅读OSDI'20的文章A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters产生的疑问,文中作者举了如图所示的例子说明CPU和PCIe switch间的通信负载也会成为通信瓶颈,并如图计算了nccl的all-reduce算法在如下情况的瓶颈负载。
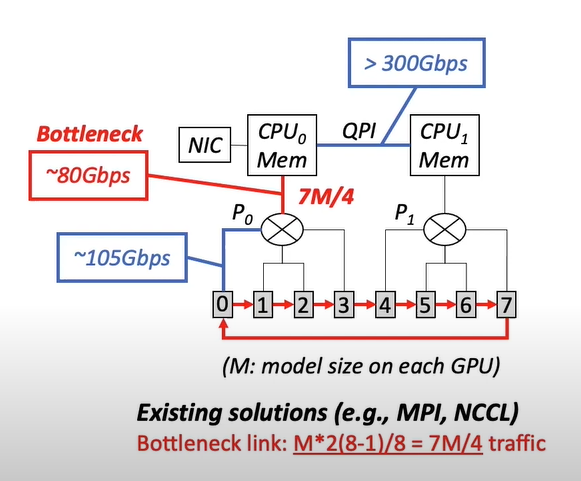 这让我好奇nccl all-reduce的计算原理是什么,以及如图所示的计算公式是怎么来的。
这让我好奇nccl all-reduce的计算原理是什么,以及如图所示的计算公式是怎么来的。
Github Issue
根据Github Issue中所言,nccl其实拥有3种不同的程序流程
- ncclAllReduce
- ncclReduceScatter + ncclAllGather
- ncclReduce + ncclBroadcast
但是问题在于
- 第1种方法是否和第2种方法等价,如果不一样,那么ncclAllReduce究竟使用的是什么方法?
- 第3种方法是不是像GPU参数服务器一样工作?
第1问
两者是不一样的。
首先ncclAllReduce会基于buffer size内在地在2和3两种方法之间切换。 其次当ncclAllReduce方法使用"reduce scatter plus allgather"算法策略的时候,从实现的角度讲依然适合使用ncclReduceScatter()和ncclAllGather是不一样的。
第2问
两者是有稍微区别的。前者算法是树状实现的,如果树的高度只有1的话,那么就很像是参数服务器的样子了。
Issue总结
其实也就是说,当我们在使用ncclAllReduce的时候,其实涉及到了前面两种方法的切换和选择,其中前者更相似于Ring的结构,后者更类似于Tree的结构。
Nvidia 文档
其实在Nccl allreduce && BytePS原理这篇博客中,记录了NCCL关于集合通信的文档,在这里可以找到NCCL中all-reduce的实现算法。
在这之前,其实要先对一些通信原语进行解释
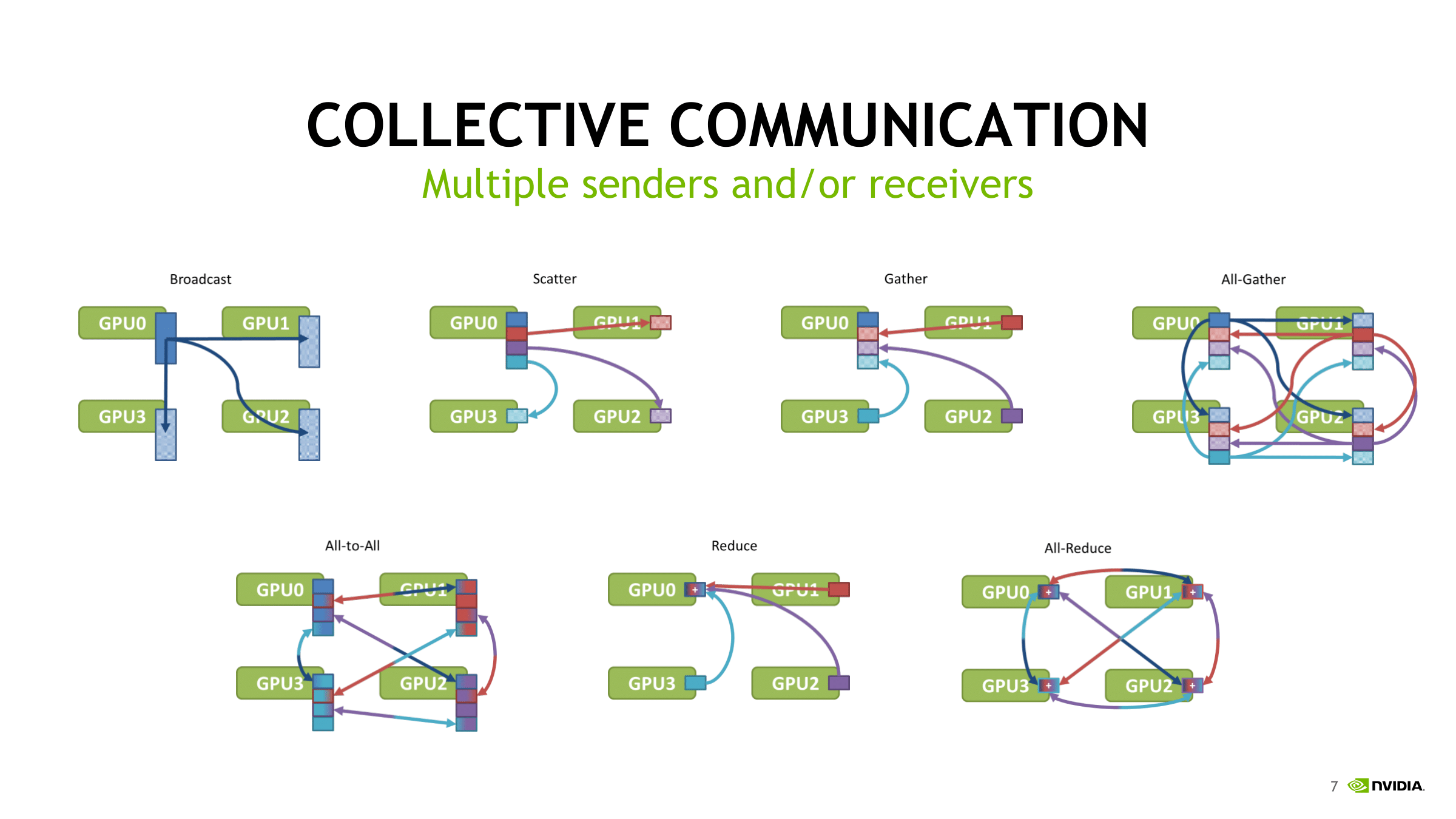
注:gather和reduce的区别在于,gather操作只是把数据不同的部分拼装在一起,而reduce是将位于不同机器上的同样类型的数据进行整合,前缀all的意义在于操作最终数据是在单独的机器上还是所有机器上。all-to-all则是从每个参与者到每个其它的参与者的直接scatter和gather。
Ring-Based Collectives
 在最初步的Ring-Based解决方法中,我们可以发现,是流水线式的从GPU0到GPU1,在下一步中由GPU1到GPU2,如此进行。如何利用流水线之间的每个流程之间的可并行性是优化的一个思路。
在最初步的Ring-Based解决方法中,我们可以发现,是流水线式的从GPU0到GPU1,在下一步中由GPU1到GPU2,如此进行。如何利用流水线之间的每个流程之间的可并行性是优化的一个思路。
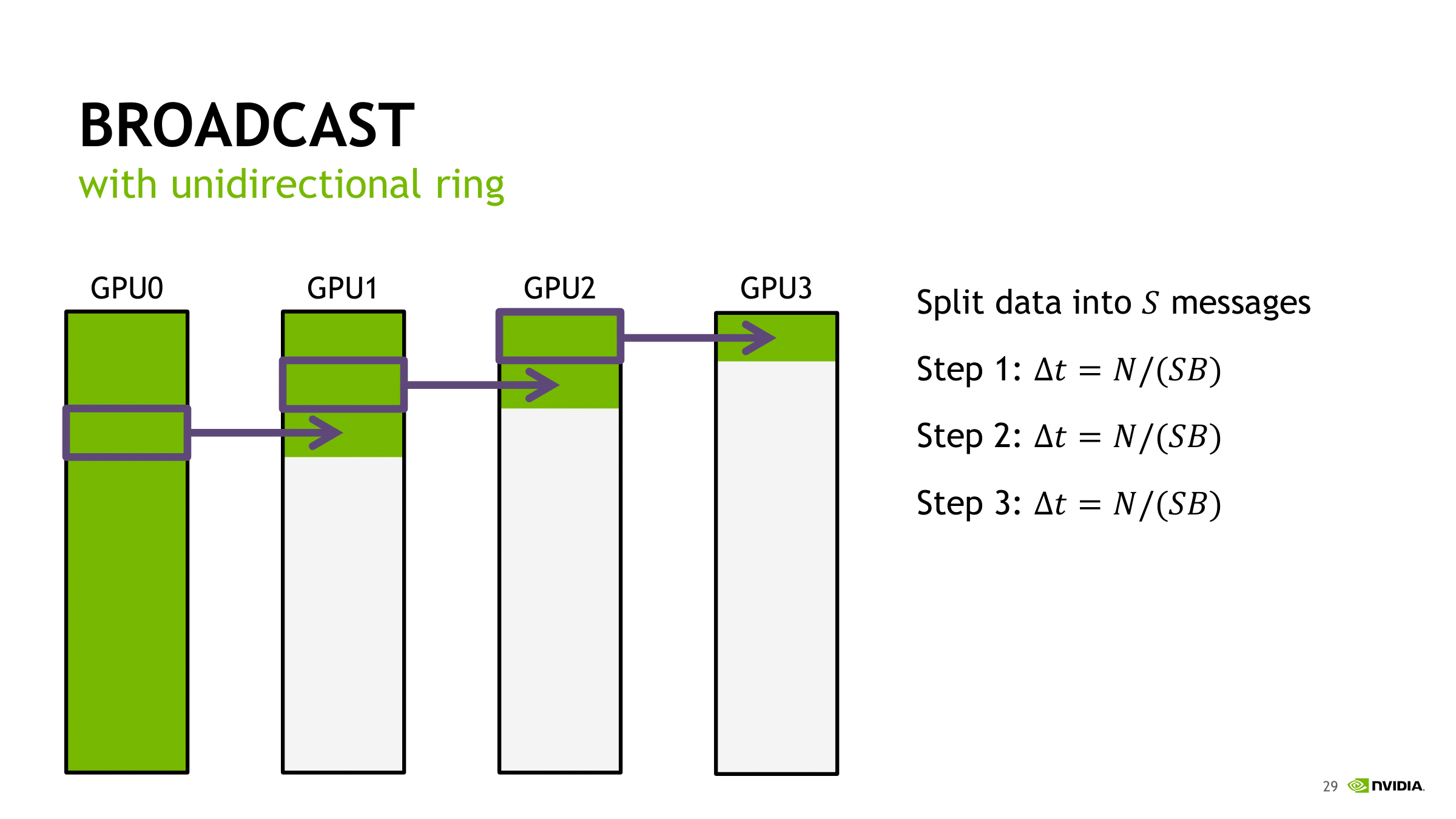
 通过将待广播的数据分为$S$份,这样在每一份数据进行转发的时候,就可以充分利用其它服务器的等待时间和带宽进行之前的数据的转发。在通常的环境中,$ S $ 会取得等于 $k$。
通过将待广播的数据分为$S$份,这样在每一份数据进行转发的时候,就可以充分利用其它服务器的等待时间和带宽进行之前的数据的转发。在通常的环境中,$ S $ 会取得等于 $k$。
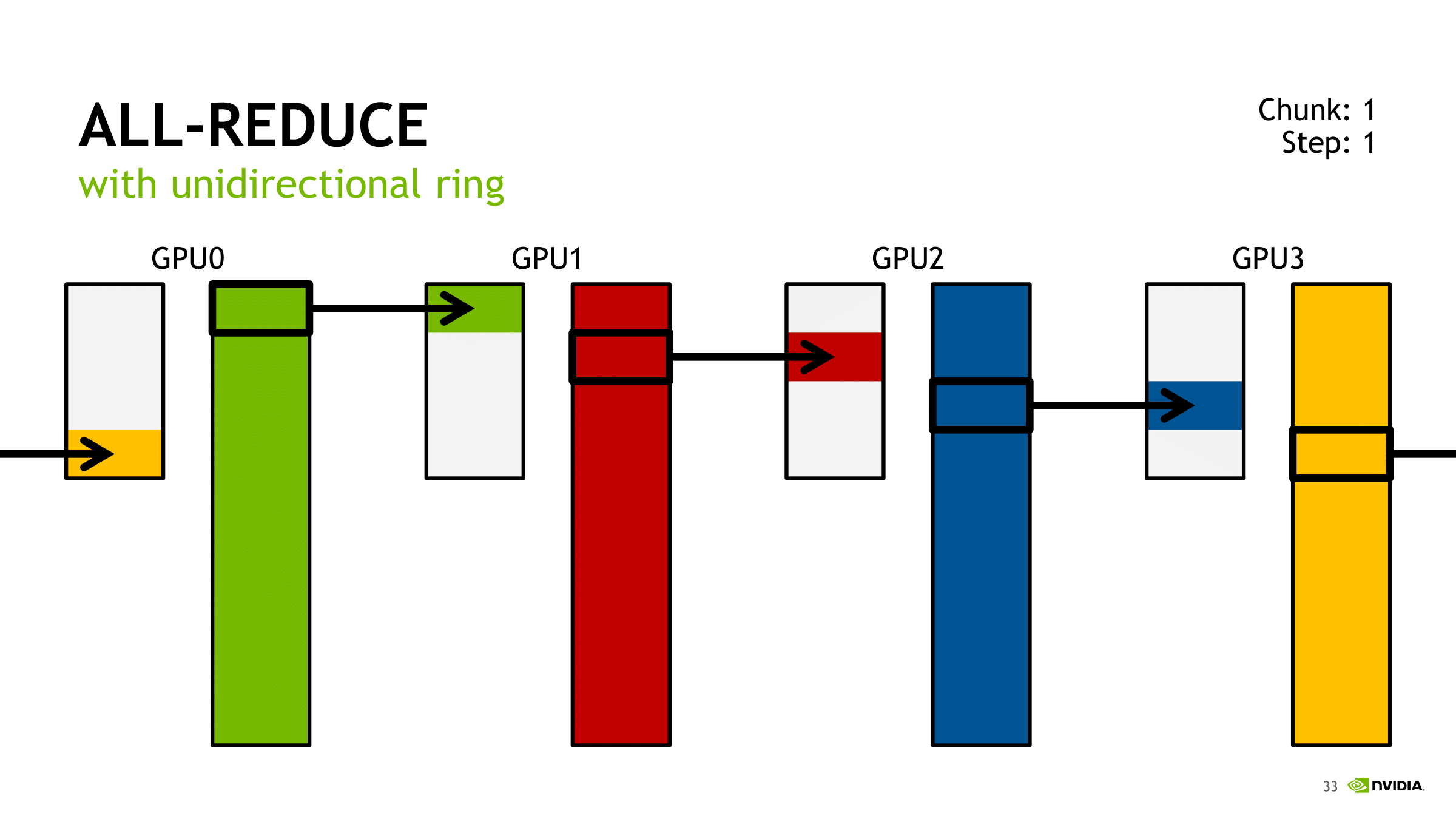
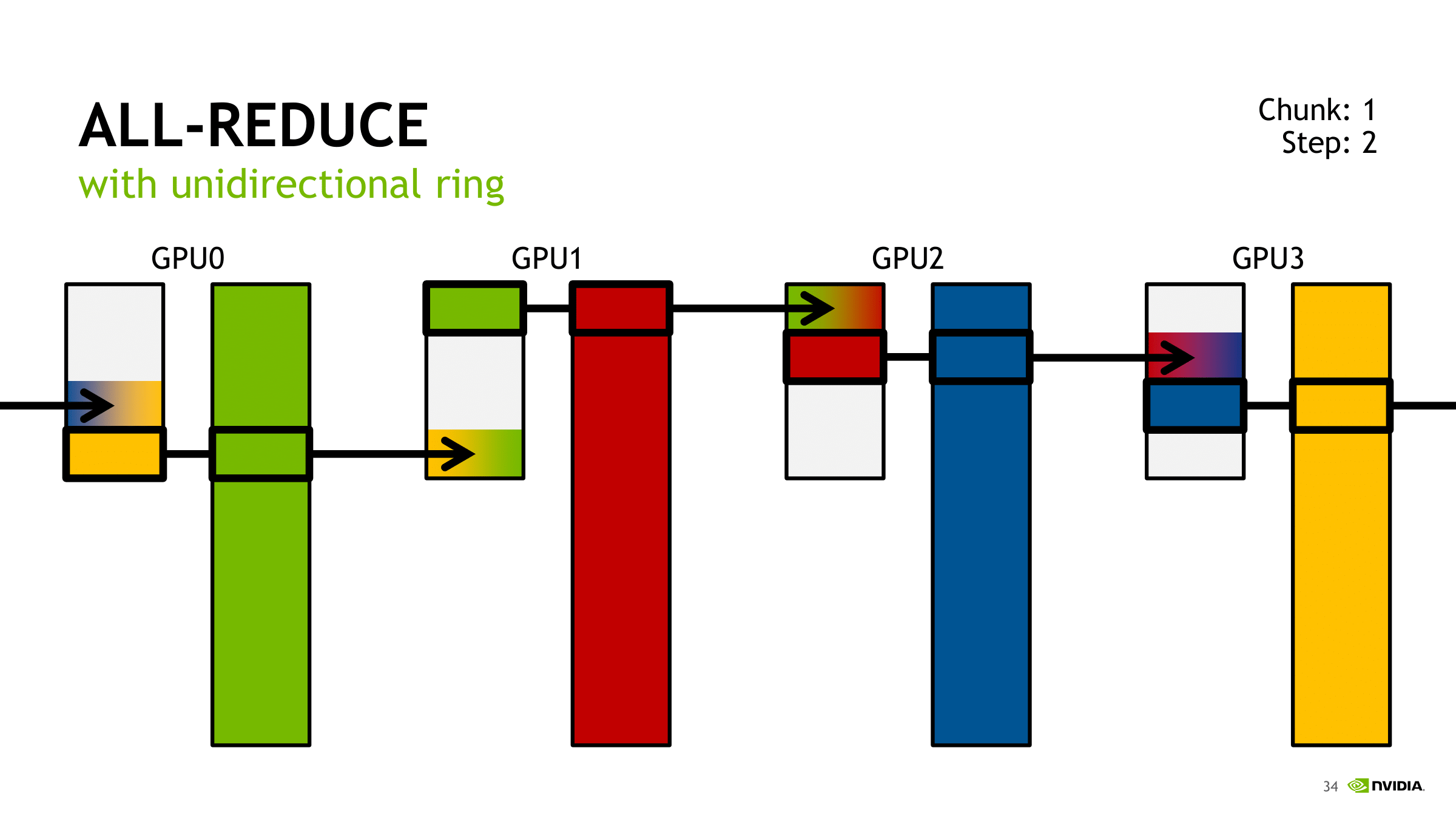
如此我们其实可以很容易理解为什么传输负载的计算公式是$$2(N-1)K/N$$
其中每次每个单独的GPU进行数据传输会发送$K/N$的数据,进行scatter会发送$N-1$次,进行broadcast会进行$N-1$。就得到了计算公式。
我们其实可以发现,在这个过程中NCCL使用的还是Ring All-Reduce方法